
一、什么是Quorum?
一句话概括,就是企业级以太坊模型。与传统的以太坊模型不同,Quorum既然是企业级应用,那么准入门槛、共识处理以及交易的安全机制上一定与传统的公链模型不同。稍后我们也将从以下几个方面详细介绍Quorum的结构模型和核心功能特色。
共识 交易机制 安全框架 网络准入门槛设置
二、Quorum交易状态
Quorum本身支持两种交易状态
公有状态:网络中所有的Quorum节点都能获得及交易内容 私有状态:只有获得相应许可的节点才能解读。两种交易核心不同就是内容是否加密。为了区别两种交易的类型,Quorum在每笔交易的签名中设置了一个特殊的value值,当签名中的value值为27或28时,表示这是一笔公开交易,如果是37或者38则是一笔私密交易。私密交易的内容会被加密,只有具有解密能力的节点才能获得具体的交易内容。
所以最终每个节点会有两套账本:一个是所有人都一样的公有账本,另一个是自己本地存储的私有账本。
所以Quorum的账本状态改变机制允许以下几种情况的调用
S -> A -> B
S -> (A) -> (B)
S -> (A) -> [B -> C]
s 表示交易发起者,(X) 表示私密, X表示公开
上述公式可以翻译为:
允许发起一笔公有交易,该公有交易合约可以调用另一个公有交易合约(公开智能合约调用公开智能合约)
允许发起一笔私有交易,该私有交易合约可以调用另一个私有交易合约(私有智能合约调用私有智能合约)
允许发起一笔私有交易,该私有交易可以只读另一个公有交易合约(私有交易读取公有账本信息,但不改变公有账本)
三、Quorum部件分析
Quorum核心分为两大块:Node节点和隐私管理。
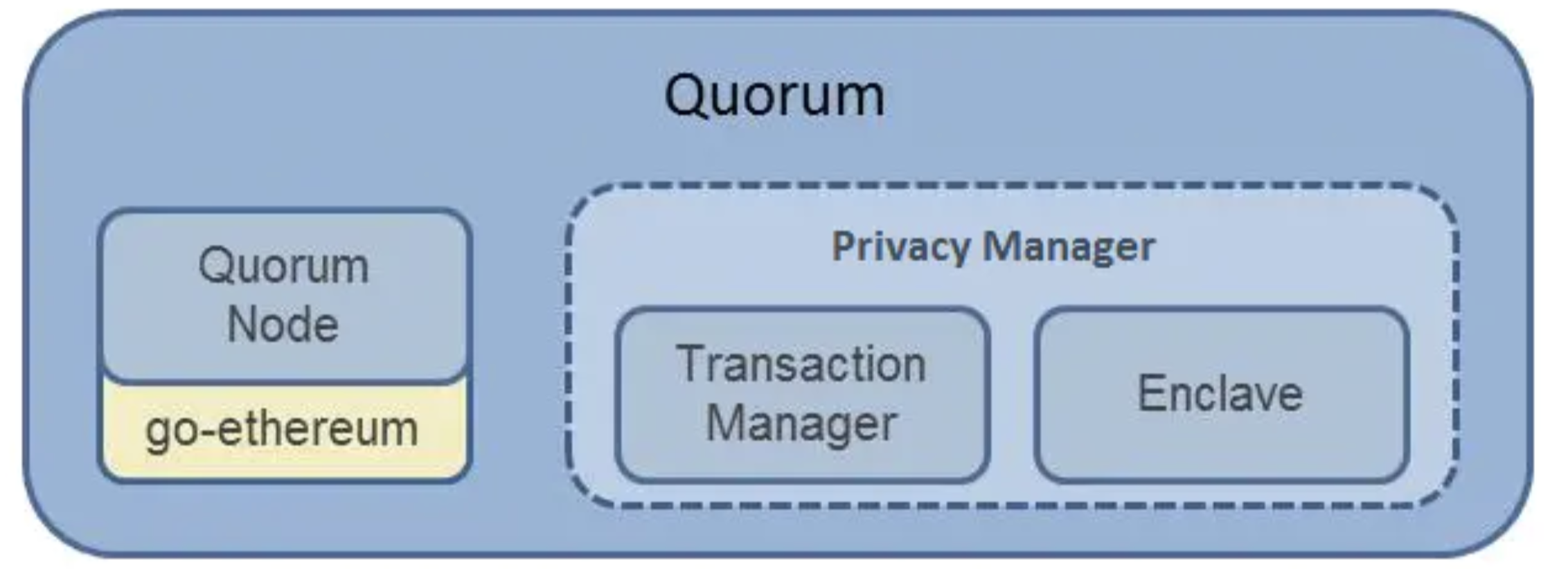
Quorum节点
Quorum节点本身是一个轻量版的Geth。沿用Geth可以发挥以太坊社区原有的研发优势,因此Quorum会随着Geth未来的版本更新而更新。
Quorum节点基于Geth做了一下改动:
使用Raft或者是IBFT共识,而不是POW共识 P2P层节点直接只进行可允许的连接(节点之间的连接必须获得许可,一般公网节点是没有接入限制的)块的产生逻辑不再是“全局账本状态”决定,而是“全局公开账本”状态决定 块的验证逻辑不再是“全局账本状态”决定,而是“全局公开账本”状态决定 账本分为两部分:公共账本和私有账本 块验证逻辑支持“私有交易”允许创建交易时交易内容是加密hash值,这样能确保私密交易的加密性 保留了gas的概念,但是交易不会产生gas费用
Quorum安全管理 - Constellation & Tessera
Constellation和Tessera(以下简称C&T)是一种用Java和Haskell实现的安全传输信息模型,他们的作用就像是网络中的信息传输代理(MTA, Message Transfer Agent)所有消息的传输都通过会话信息秘钥进行加密
PGP加密, 可以用来发送机密消息。这是通过对称的一组密钥-公钥组合来实现的。消息采用对称加密算法加密,采用一组对称密钥。每个对称密钥只使用一次,所以也叫做会话密钥。
C&T其实是一种多方参与网络中实现个人消息加密的常用组件,在许多应用中都很常见,并不是区块链领域专有技术(笔者注,其实区块链本身就是各种技术的大杂烩,我们很难专门找到一门技术,说它就是区块链 )。C&T主要包括两个子模块:
The Node Quorum使用这个模块实现了PrivateTransactionManager 私有交易管理 The Enclave
Transaction Manager 交易管理
交易管理模块主要负责交易的隐私,包括存储私密交易数据、控制私密交易的访问、与其他参与者的交易管理器进行私密交易载荷的交换。Transaction Manager 本身并不涉及任何私钥和私钥的使用,所有数字加密模块的功能都由The Enclave来完成。
Transaction Manager属于静态/Restful模组,能够非常容易的被加载。
The Enclave
分布式账本协议通常都会涉及交易验证、参与者授权、历史信息存储(通过hash链)等。为了在加密这一方面实现平行操作的性能扩展和,所有公私钥生成、数据的加密/解密都由Enclave模块完成。
三、Quorum共识
我们知道,公共区块链是一个开放的社区,任何人都能够成为一个节点加入网络,在网络中计算,提交交易到链上等,因此公链是没有信任基础的,所以公链的共识第一要义就是证明交易的合法性和真实性,防止恶意成员的捣乱,效率不是第一要义。
与公链的环境不同,有准入门槛的企业链或者联盟链链上的所有成员在加入时实际上是已经获得了某些认可和许可的,因此企业链/联盟链上的成员是有一定信任基础的。在企业级链上我们没有必要使用POW或者POS这种浪费算力或者低效的交易共识。
Quorum提供了多种共识供用户采用:
Raft-based Consensus Raft共识(在联盟链Hyperledger Fabric中也支持此种共识算法)Istanbul BFT (Byzantine Fault Tolerance) Consensus IBFT共识 Clique POA共识
Raft
1.什么是Raft
在讲Raft前,有必要提一下Paxos算法,Paxos算法是Leslie Lamport于1990年提出的基于消息传递的一致性算法。然而,由于算法难以理解,刚开始并没有得到很多人的重视。其后,作者在八年后,也就是1998年在ACM上正式发表,然而由于算法难以理解还是没有得到重视。而作者之后用更容易接受的方法重新发表了一篇论文《Paxos Made Simple》。
可见,Paxos算法是有多难理解,即便现在放到很多高校,依然很多学生、教授都反馈Paxos算法难以理解。同时,Paxos算法在实际应用实现的时候也是比较困难的。这也是为什么会有后来Raft算法的提出。
Raft是实现分布式共识的一种算法,主要用来管理日志复制的一致性。它和Paxos的功能是一样,但是相比于Paxos,Raft算法更容易理解、也更容易应用到实际的系统当中。而Raft算法也是联盟链采用比较多的共识算法。
角色
Raft一共有三种角色状态:
Follower(群众)被动接收Leader发送的请求。所有的节点刚开始的时候是处于Follower状态。Candidate(候选人)由Follower向Leader转换的中间状态 Leader(领导)负责和客户端交互以及日志复制(日志复制是单向的,即Leader发送给Follower),同一时刻最多只有1个Leader存在。
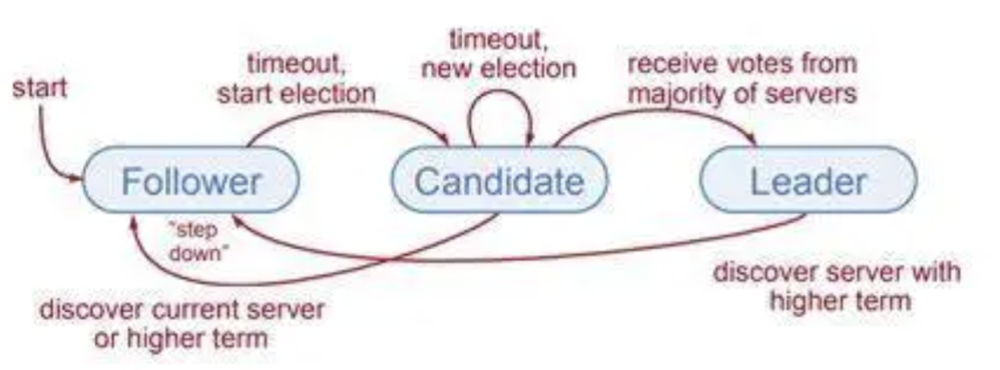
每个节点上都有一个倒计时器 (Election Timeout),时间随机在 150ms 到 300ms 之间。有几种情况会重设 Timeout:
收到选举的请求 收到 Leader 的 Heartbeat
任期
在分布式系统中,“时间同步”是一个很大的难题,因为每个机器可能由于所处的地理位置、机器环境等因素会不同程度造成时钟不一致,但是为了识别“过期信息”,时间信息必不可少。
Raft算法中就采用任期(Term)的概念,将时间切分为一个个的Term(同时每个节点自身也会本地维护currentTerm),可以认为是逻辑上的时间,如下图。
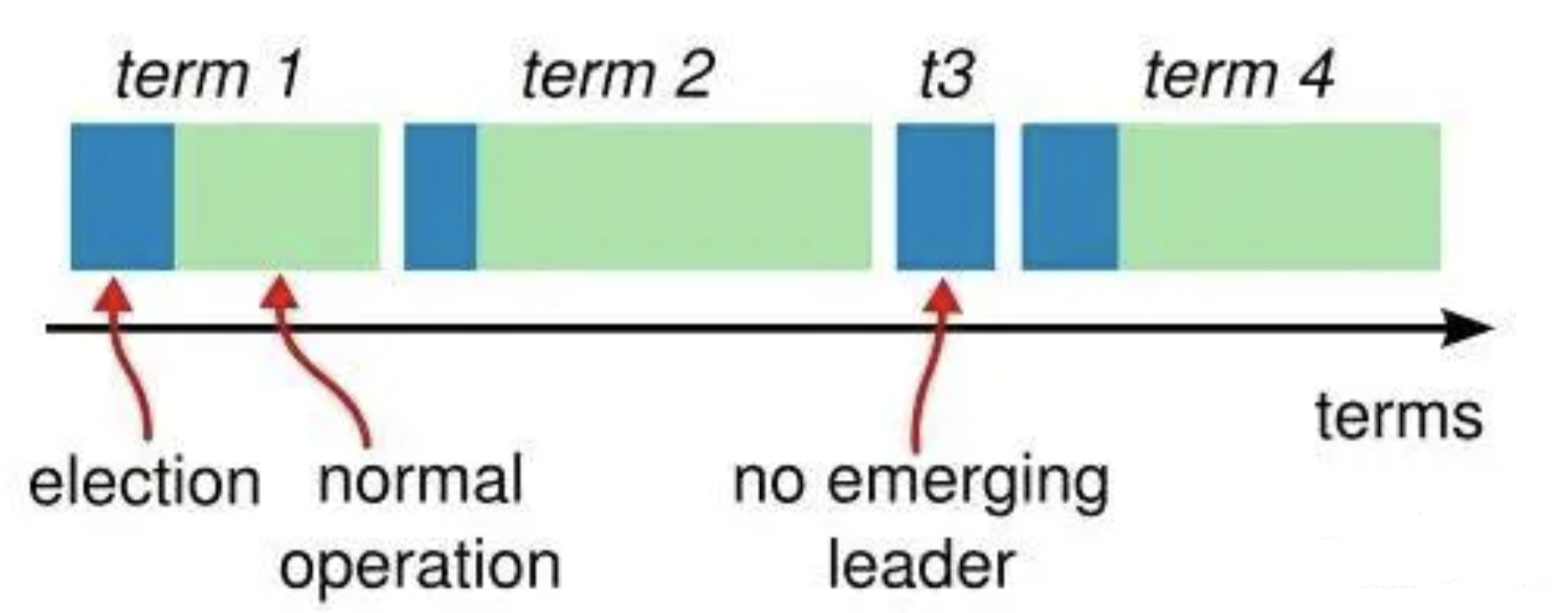
每一任期的开始都是一次领导人选举,一个或多个候选人(Candidate)会尝试成为领导(Leader)。如果一个人赢得选举,就会在该任期(Term)内剩余的时间担任领导人。在某些情况下,选票可能会被评分,有可能没有选出领导人(如t3),那么,将会开始另一任期,并且立刻开始下一次选举。Raft 算法保证在给定的一个任期最少要有一个领导人。
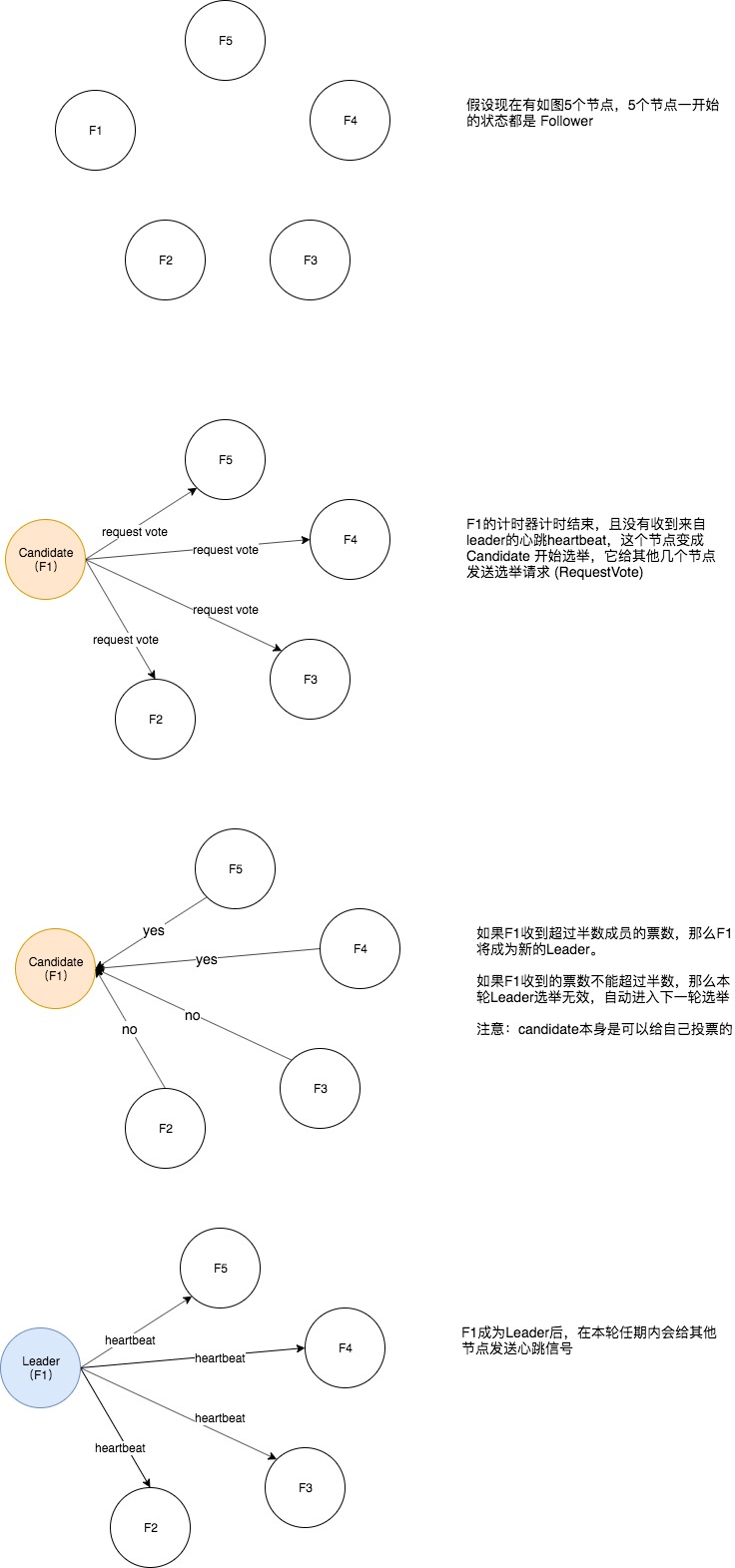
Leader选举
特殊情况的处理
多个候选人
票数多的候选人成为leader 如果候选人平票,则本轮选举无效,进入下一轮选举。此时所有本轮的candidate + follower中先结束计时器的成为下一轮的候选人 新的leader产生后会向所有的节点发送heartbeat,这个时候剩余candidate自动恢复follower身份
已有follower故障 剩余的节点因为没有收到来自leader的心跳信息,所以自动进入选举状态,选出新的leader(L2)
L2工作期间如果旧leader(L1)故障恢复上线,因为L2的任期比L1的任期要新,所以其他节点只认L2的指令。L1在接收到L2的心跳之后也会自动降级成为Follower
日志记录

2.以太坊中的Raft共识
在以太坊中节点本身并没有角色,因此在使用Raft共识时,我们称leader节点为挖矿节点:
只有挖矿节点有权产生新的块,而不用对自己的工作进行证明。如果一个以太坊节点成为leader,那么它就会开始挖矿;如果它不再是leader,那么它就停止挖矿
Raft共识机制本身保证了同一时间点最多只有一个leader,因此用在以太坊模型下也只会有一个出块者,避免了同时出块或者算力浪费的情况。
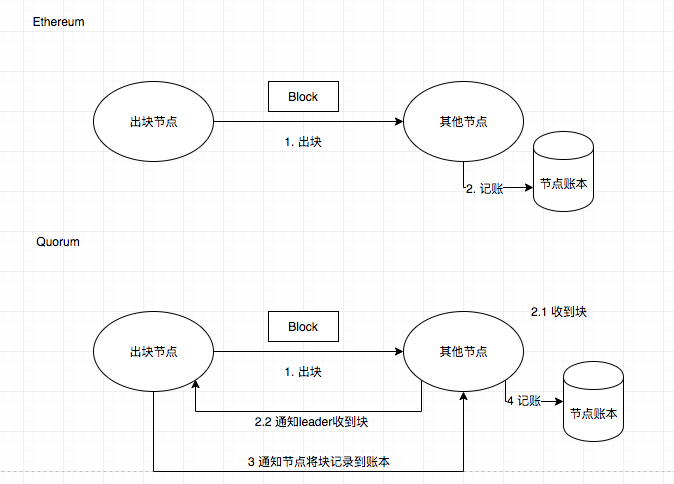
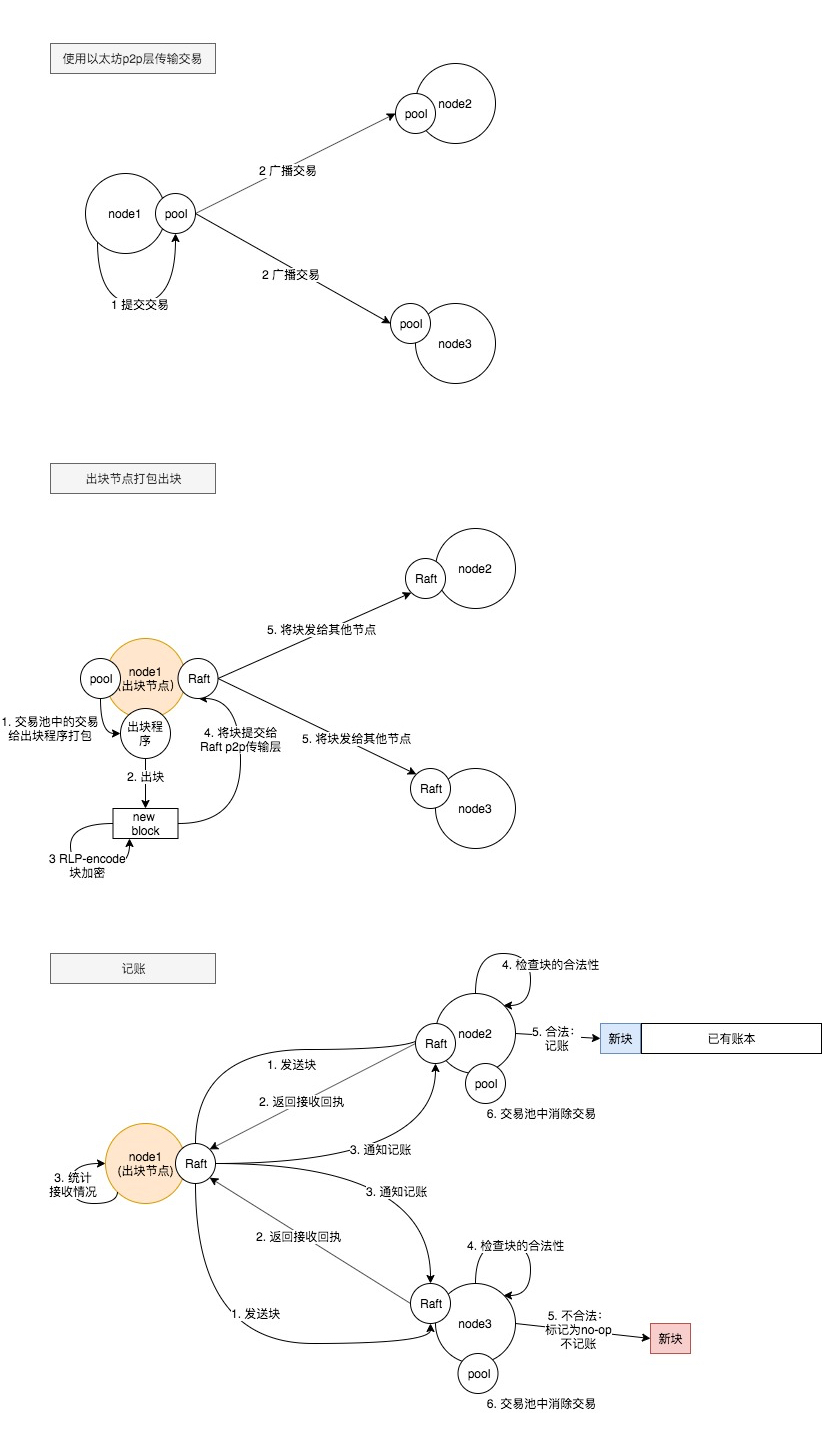
在单笔交易(transaction)层级Quorum依然沿用了Ethereum的p2p传输机制,只有在块(block)层级才会使用Raft的传输机制。
其中需要注意到一点,在以太坊中一个节点收到块以后就会立刻记账,而在Quorum模型中,一个块的记录必须遵从Raft协议,每个节点从leader处收到块以后必须报告给leader确认收到以后,再由leader通知各个节点进行数据提交(记录)
Quorum中一笔交易的生命周期
链的延伸、竞争和校准
在Quorum模型中新块的信息是很有可能和已有块的header信息不符的,最容易发生这种情况的就是选举人更替(挖矿节点更替),具体描述如下:
time block submissions
node 1 node 2
| [ 0xbeda Parent: 0xacaa ]
|
| -- 1 is partitioned; 2 takes over as leader/minter --
|
| [ 0x2c52 Parent: 0xbeda ] [ 0xf0ec Parent: 0xbeda ]
| [ 0x839c Parent: 0xf0ec ]
|
| -- 1 rejoins --
|
v [ 0x8b37 Parent: 0x839c ]
假设有两个节点,node1和node2,node1是现有的leader,现有链的最新区块是0xbeda,它的父区块是0xacaa
假设node 1产生故障和网络中的其他节点通讯不上,在此期间node1产生了新的块0x2c52 node1故障期间 node2被选举成为了新的挖矿节点(leader),产生了两个新的区块0xf0ec 和 0x839c。其中0xf0ec已经被其他节点记账
假设node1恢复了通信,将0x2c52发送给其他节点,因为0x2c52的parent和现有的其他节点的最新区块header不一致,所以会被标记为no-op 无效区块 而node2 发送的0x839c的parent和其他节点最新区块的header一致,所以会被其他节点接收,标记为extends 有效区块,记录在账本上
对块“Extends”或者“No-op”的标记是在更上层完成的,并不由raft本身log记录机制实现。因为在raft内部,信息并不分为有效或无效,只有在区块链层面才会有有效区块和无效区块的含义。
需要注意的是,Quorum的这种记账机制和本身Ethereum的LVC(最长链机制)是完全不一样的
LVC是为了解决链分叉问题 Raft本身的记账特性就决定了Quorum不会产生链的分叉
出块频率
Quorum的出块频率默认是50ms一个块,可以通过 --raftblocktime 参数进行设置
投机性出块
投机性出块并不是以太坊Raft共识严格必须的核心机制之一,但是是提高出块效率的有效方式。
一个块从产生到实际被记录账本,走完整个raft流程实际上是需要耗费一定时间的。如果我们在上一个块被计入账本之后才开始产生下一个块,那么一笔交易想要成功被记录需要耗费较多的时间。
而在投机性(speculative minting)出块中,我们允许一个新块在它的父块被记录之前就产生。依次类推,在一段时间内,实际上会产生“投机链(speculative chain)”,在祖先块没有被记录进账本之前,一个一个新块已经依据先后关系组成了一条临时链片段,等待被记录。
对于已经被记录进投机块的交易,我们会在交易池中标记为“proposed transaction”
在之前我们说过,raft机制中是存在两个挖矿节点比赛出块和记账的可能的,因此,一条 speculative chain 中间的某一个块很有可能不会被记录到账本中。在这种情况下我们也会把交易池中的交易状态修改回来。(InvalidRaftOrdering event)
目前,Quorum并没有对speculative chain的长度做限制,但在它的未来规划中有讲这一点作为一个性能优化项加入开发进程,最后能够让一个挖矿节点即使在raft共识层没有连接上,它也可以离线一直出块,产生自己的speculative chain。
一条speculative chain有以下几个部分构成:
head: 最先创建的块,如果最先创建的块已经被记录进区块链,head值为nil
proposedTxes: 已经进入raft共识层,但还没有被计入账本的交易
unappliedBlocks: 一个块队列,包含那些已经进入raft共识层但还没有被记录进区块链账本的块
挖矿节点产生一个新块的时候,执行enqueue(new block)
accept 方法:当队列头部的块被记录进账本的时候,对这个块执行accept方法。
当InvalidRaftOrdering 事件发生时,将队列尾部的块全部pop up,直到所有依赖无效块的新块全部被pop up。
expectedInvalidBlockHashes: 构建在无效块上但尚未通过 Raft 的块集(注意,已经通过raft共识层但还没有被记录账本的是unappliedBlocks,unappliedBlocks是有可能包含无效块的,详见上一条)。有时我们会用这些块集作为“guard”来避免对speculative chain的不必要修剪行为
Raft传输层
在块传输上我们使用etcd Raft默认的http传输,当然使用Ethereum的p2p传输也是可以的,但是Quorum团队在测试阶段发现,高负载的状态下,ETH p2p的性能没有raft p2p性能好。
Quorum使用50400端口作为Raft 传输层的默认监听端口,也可以通过--raftport 参数自行设置。
一个集群默认的最大节点个数是25,可以通过--maxpeers N来设置,N是你的最大节点个数。
IBFT共识
Quorum的IBFT其实就是PBFT,只不过摩根大通把它自己实现的PBFT叫做IBFT,所以IBFT的基本原理与PBFT是一样的,所不同的是,IBFT中把出块和共识的三阶段结合在了一起。
IBFT工作原理流程
Istanbul BFT修改自PBFT算法,包括三个阶段:PRE-PREPARE、PREPARE以及COMMIT。在N个节点的网络中,这个算法可以最多容忍F个出错节点,其中N=3F+1。
在每一轮开始前,validator会选择其中一个作为proposer,默认以轮询的方式(除此之外还有sticky的方式,搜索stickyProposer方法去看细节)。
proposer会提出一个区块的proposal,并且广播PRE-PREPARE信息。
一旦一个validator收到PRE-PREPARE信息,会把状态标记为PRE-PREPARED,然后广播PREPARE信息。这一步是为了确保所有的validator在同一个seqnence(proposal的高度)和round上进行共识验证。
一旦收到2F+ 1个PREPARE信息,validator进入PREPARED状态然后广播COMMIT信息。这一步是为了通知节点的peer已经接收到了提出的区块,并且即将插入区块到链中。
最后,validator等待2F + 1个COMMIT信息,然后进入COMMITTED状态然后插入区块到链中。Istanbul BFT算法中的区块是确定的,意味着链没有分叉并且合法的区块一定是在链中。为了防止一个恶意节点生成不同的链,在把区块插入进链之前,每一个validator必须把2F + 1个COMMIT签名放进区块头的extraData字段。因此,区块是可以自我验证的(因为有签名)并且轻客户端也支持。
然而动态的extraData也会造成区块的hash计算问题。因为一个区块可以被不同的validator验证,所以会有不同的签名,所以同一个区块会有不同的hash。解决的方案是,计算区块hash的时候把COMMIT签名排除在外。因此我们任然可以在保证block hash一致性的同时进行共识验证。
IBFT中的状态与状态转换
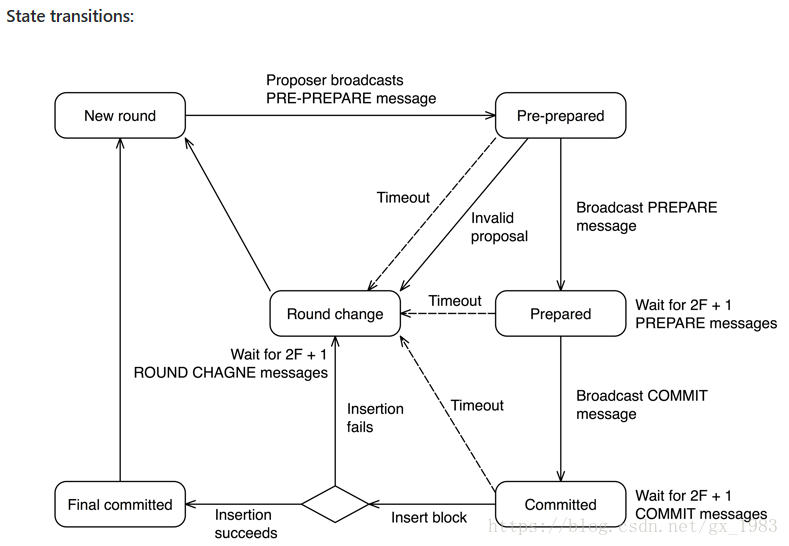
状态介绍
New Round: 一个proposer发送新的区块proposal。validator等待PRE-PREPARE信息。PRE-PREPARED: 一个validator已经收到PRE-PREPARE信息,并且广播PREPARE信息。然后等待2F + 1个PREPARE或者COMMIT信息。PREPARED: 一个validator已经收到2F + 1个PREPARE信息,此时把自身状态标记为PREPARED,并且广播COMMIT信息。然后等待2F + 1个COMMIT信息
COMMITTED: 一个validator已经收到2F + 1个COMMIT信息,此时把自身状态标记为COMMITTED,并且开始把提出的block插入链中。FINAL COMMITTED: 一个validator已经成功把区块成功插入了链中,此时把自身状态标记为FINAL COMMITTED,并且等待下一轮。ROUND CHANGE: 一个validator等待关于同一个round下的2F + 1个ROUND CHANGE信息。状态转换
NEW ROUND -> PRE-PREPARED:
Proposer在txpool中收集交易。Proposer提出一个区块proposal并且广播给validator。然后进入PRE-PREPARED状态。每一个validator进入到PRE-PREPARED状态,一旦收到PRE-PREPARED信息并且伴随着以下情况:
区块proposal是来自于有效的proposer。区块头有效。区块proposal的sequence和round和validator的状态匹配。Validator广播PREPARE信息给其他validators。PRE-PREPARED -> PREPARED:
Validator收到2F + 1个有效的PREPARE信息,因此而进入PREPARED状态。有效信息需要满足以下条件:sequence和round匹配。交易hash匹配。信息是来自已知的validators。一旦进入PREPARED状态,Validator广播COMMIT信息。PREPARED -> COMMITTED:
Validator收到2F + 1个有效的COMMIT信息,以此进入COMMITTED状态。有效的信息需要满足以下条件:sequence和round匹配。block hash匹配
信息是来自已知的validators。COMMITTED -> FINAL COMMITTED:
Validator把2F + 1个commitment签名放进区块头的extraData并且尝试插入区块进区块链。当插入区块成功,Validator进入FINAL COMMITTED状态。FINAL COMMITTED -> NEW ROUND:
Validators选一个新的proposer开始新的一轮。
Clique POA共识
由于Ethereum POA共识在网上已经有大量介绍,笔者这里就不多做详细介绍,只对重要特点和POA的工作流程做大致梳理和介绍
PoA的特点
PoA是依靠预设好的授权节点(signers),负责产生block.
可以由已授权的signer选举(投票超过50%)加入新的signer。即使存在恶意signer,他最多只能攻击连续块(数量是 (SIGNER_COUNT / 2) + 1) 中的1个,期间可以由其他signer投票踢出该恶意signer。可指定产生block的时间。POA工作流程
在创世块中指定一组初始授权的signers, 所有地址 保存在创世块Extra字段中
启动挖矿后, 该组signers开始对生成的block进行 签名并广播。签名结果 保存在区块头的Extra字段中
Extra中更新当前高度已授权的 所有signers的地址 ,因为有新加入或踢出的signer
每一高度都有一个signer处于IN-TURN状态, 其他signer处于OUT-OF-TURN状态, IN-TURN的signer签名的block会 立即广播 , OUT-OF-TURN的signer签名的block会 延时 一点随机时间后再广播, 保证IN-TURN的签名block有更高的优先级上链
如果需要加入一个新的signer, signer通过API接口发起一个proposal, 该proposal通过复用区块头 Coinbase(新signer地址)和Nonce("0xffffffffffffffff") 字段广播给其他节点. 所有已授权的signers对该新的signer进行"加入"投票, 如果赞成票超过signers总数的50%, 表示同意加入
如果需要踢出一个旧的signer, 所有已授权的signers对该旧的signer进行"踢出"投票, 如果赞成票超过signers总数的50%, 表示同意踢出
Quorum权限体系
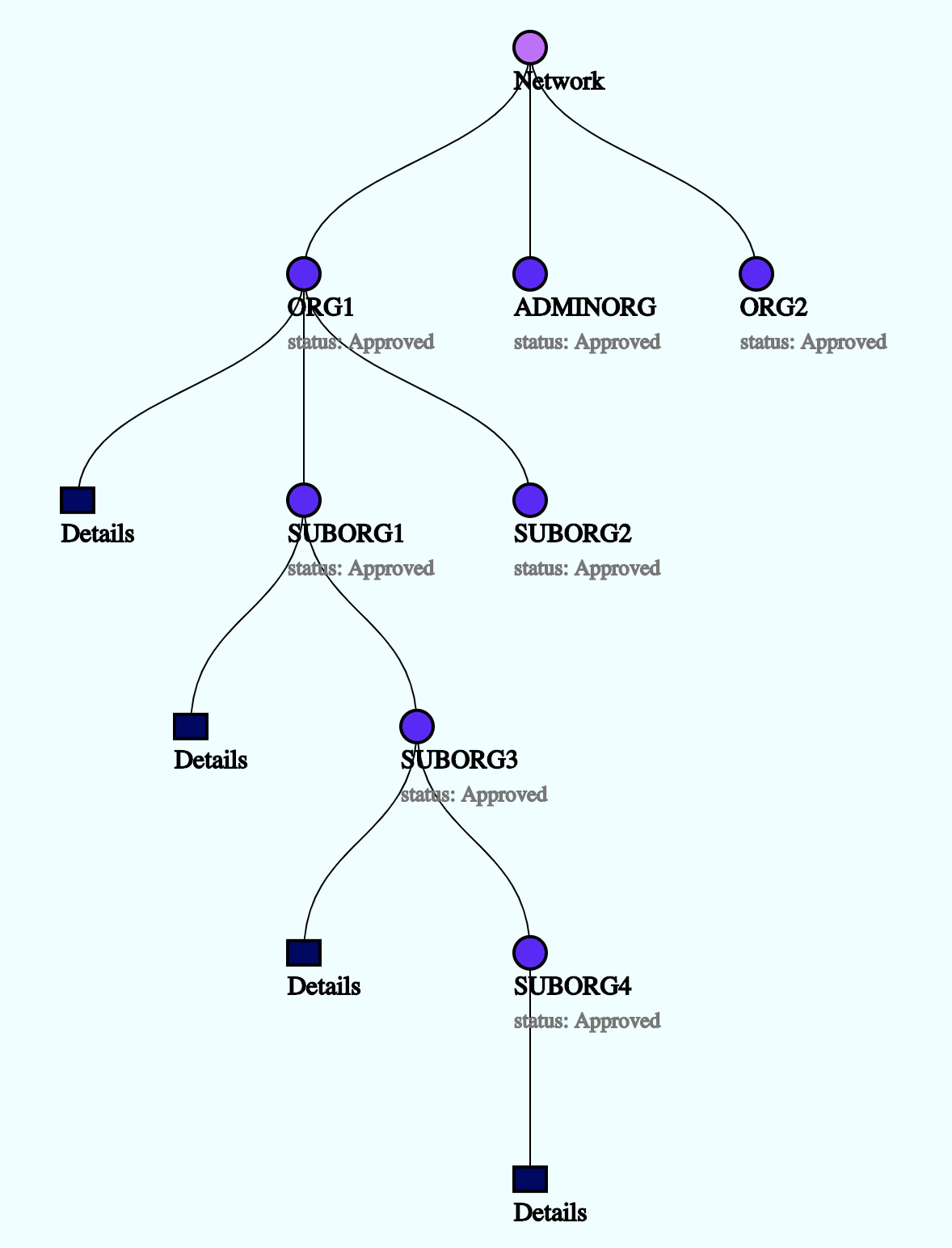
Quorum目前的许可系统只限于节点等级的许可,只有在permission-nodes.json文件中定义的节点才能够加入网络。这个准许模型已经要被优化成基于智能合约的授权许可模型,新模型在管理节点、账户和账户权限管理上都有一定灵活度,整体框架模型如下图所示

在优化模型结构图中,一个网络聚合了一群组织。网络层级有网络管理员账号,网络管理员可以提议和投票新组织加入网络,也可以指定某个账号为机构管理员账号。
机构管理员账号可以创建机构内角色、子机构、为自己机构下的账号赋予某种角色的功能,指定某个节点为本机构节点。子机构也可以创建自己的角色、子机构、节点。。。机构管理账号在机构层面管理和控制各项行为活动。父级机构管理原可以创建管理员角色,并将该角色的功能赋予其他账号。
智能合约设计
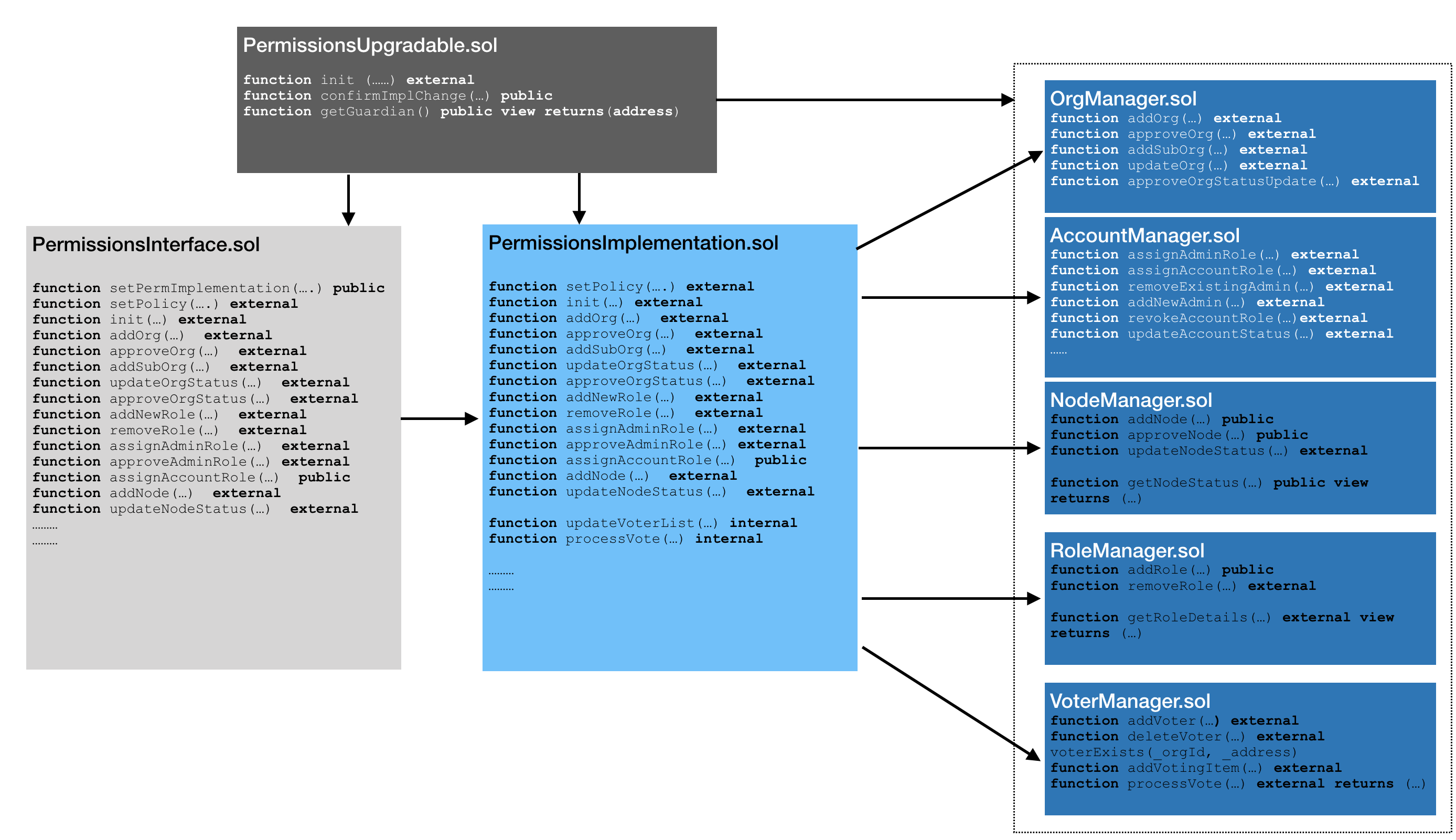
Quorum权限系统智能合约的设计遵循Proxy-Implementation-Storage pattern(代理-实现-存储 模式),采用该模式可以保证及时业务逻辑层改变,也不会影响数据存储层和接口层的。智能合约的具体描述如下:
PermissionsUpgrade.sol存储implementation合约的地址,这份合约地址只有guardian账户可以操作改变
PermissionsInterface.sol接口定义,不含任何业务逻辑,会将接收到的请求转发给业务合约
PermissionsImplementation.sol包含所有授权系统的操作逻辑。只接收在 PermissionsUpgradable.sol 中定义的接口请求,并根据相应操作和对应的存储合约交互
OrgManager.sol存储机构和子机构信息,只接受来自 PermissionsUpgrade.sol合约中定义的implementation合约地址的请求
AccountManager.sol存储所有账户相关的信息,包括账户和组织和归属关系,一个账户地址有哪些权限等。同时也存储一个账号的状态:PendingApproval, Active, Inactive, Suspended, Blacklisted or Revoked
NodeManager.sol存储所有和节点相关的数据,包括节点和机构、子机构的关系,节点的状态: PendingApproval, Approved, Deactivated or Blacklisted
RoleManager.sol同样只接收在 PermissionsUpgrdable.sol定义的implementation合约的请求。 存储角色和组织的关系。角色能够包括的权限如下:
Readonly只读权限
Transact 只能交易,不能部署合约
ContractDeploy 可以交易,也可以部署合约
FullAccess 全权限
如果一个角色被撤销,那么所有被赋予这个角色的账户都会失去角色原有的权限。
VoterManager.sol存储网络管理员信息。在创建网络时会预先定义一系列的网路管理员账号,这些账号都会被记录在本合约中。一旦网络层级有需要投票的事件发生,投票事件也会被记录在本合约中。权限模型的部署
部署网络初始节点 部署PermissionsUpgradable.sol合约。部署该合约时,作为参数需要指定一个guardian账号地址 部署剩余的合约。部署剩余合约的时候都需要PermissionsUpgradable.sol合约地址作为部署参数 所有合约部署完成后,按以下格式创建permission-config.json文件
{
"upgradableAddress": "0x1932c48b2bf8102ba33b4a6b545c32236e342f34",
"interfaceAddress": "0x4d3bfd7821e237ffe84209d8e638f9f309865b87",
"implAddress": "0xfe0602d820f42800e3ef3f89e1c39cd15f78d283",
"nodeMgrAddress": "0x8a5e2a6343108babed07899510fb42297938d41f",
"accountMgrAddress": "0x9d13c6d3afe1721beef56b55d303b09e021e27ab",
"roleMgrAddress": "0x1349f3e1b8d71effb47b840594ff27da7e603d17",
"voterMgrAddress": "0xd9d64b7dc034fafdba5dc2902875a67b5d586420",
"orgMgrAddress" : "0x938781b9796aea6376e40ca158f67fa89d5d8a18",
"nwAdminOrg": "ADMINORG",
"nwAdminRole" : "ADMIN",
"orgAdminRole" : "ORGADMIN",
"accounts":["0xed9d02e382b34818e88b88a309c7fe71e65f419d", "0xca843569e3427144cead5e4d5999a3d0ccf92b8e"],
"subOrgBreadth" : 3,
"subOrgDepth" : 4
}
使用guardian account调用PermissionsUpgradable.sol的init服务
使用geth加载以下内容
ac = eth.accounts[0];
web3.eth.defaultAccount = ac;
var abi = [{"constant":true,"inputs":[],"name":"getPermImpl","outputs":[{"name":"","type":"address"}],"payable":false,"stateMutability":"view","type":"function"},{"constant":false,"inputs":[{"name":"_proposedImpl","type":"address"}],"name":"confirmImplChange","outputs":[],"payable":false,"stateMutability":"nonpayable","type":"function"},{"constant":true,"inputs":[],"name":"getGuardian","outputs":[{"name":"","type":"address"}],"payable":false,"stateMutability":"view","type":"function"},{"constant":true,"inputs":[],"name":"getPermInterface","outputs":[{"name":"","type":"address"}],"payable":false,"stateMutability":"view","type":"function"},{"constant":false,"inputs":[{"name":"_permInterface","type":"address"},{"name":"_permImpl","type":"address"}],"name":"init","outputs":[],"payable":false,"stateMutability":"nonpayable","type":"function"},{"inputs":[{"name":"_guardian","type":"address"}],"payable":false,"stateMutability":"nonpayable","type":"constructor"}];
var upgr = web3.eth.contract(abi).at("0x1932c48b2bf8102ba33b4a6b545c32236e342f34"); // address of the upgradable contracts
var impl = "0xfe0602d820f42800e3ef3f89e1c39cd15f78d283" // address of the implementation contracts
var intr = "0x4d3bfd7821e237ffe84209d8e638f9f309865b87" // address of the interface contracts
执行 upgr.init(intr, impl, {from: \<guardian account>, gas: 4500000})
关闭所有geth节点,并将permission-config.json文件拷贝进每个节点的data文件夹下
将所有geth节点以 --permissioned 方式启动
API文档
https://docs.goquorum.com/en/latest/Permissioning/Permissioning%20apis/
使用方法
初始化网络
假设初始节点的配置文件static-nodes.json的内容如下:
[
"enode://72c0572f7a2492cffb5efc3463ef350c68a0446402a123dacec9db5c378789205b525b3f5f623f7548379ab0e5957110bffcf43a6115e450890f97a9f65a681a@127.0.0.1:21000?discport=0",
"enode://7a1e3b5c6ad614086a4e5fb55b6fe0a7cf7a7ac92ac3a60e6033de29df14148e7a6a7b4461eb70639df9aa379bd77487937bea0a8da862142b12d326c7285742@127.0.0.1:21001?discport=0",
"enode://5085e86db5324ca4a55aeccfbb35befb412def36e6bc74f166102796ac3c8af3cc83a5dec9c32e6fd6d359b779dba9a911da8f3e722cb11eb4e10694c59fd4a1@127.0.0.1:21002?discport=0",
"enode://28a4afcf56ee5e435c65b9581fc36896cc684695fa1db83c9568de4353dc6664b5cab09694d9427e9cf26a5cd2ac2fb45a63b43bb24e46ee121f21beb3a7865e@127.0.0.1:21003?discport=0"
]
网络的权限配置如下
> quorumPermission.orgList
[{
fullOrgId: "ADMINORG",
level: 1,
orgId: "ADMINORG",
parentOrgId: "",
status: 2,
subOrgList: null,
ultimateParent: "ADMINORG"
}]
> quorumPermission.getOrgDetails("ADMINORG")
{
acctList: [{
acctId: "0xed9d02e382b34818e88b88a309c7fe71e65f419d",
isOrgAdmin: true,
orgId: "ADMINORG",
roleId: "ADMIN",
status: 2
}, {
acctId: "0xca843569e3427144cead5e4d5999a3d0ccf92b8e",
isOrgAdmin: true,
orgId: "ADMINORG",
roleId: "ADMIN",
status: 2
}],
nodeList: [{
orgId: "ADMINORG",
status: 2,
url: "enode://72c0572f7a2492cffb5efc3463ef350c68a0446402a123dacec9db5c378789205b525b3f5f623f7548379ab0e5957110bffcf43a6115e450890f97a9f65a681a@127.0.0.1:21000?discport=0"
}, {
orgId: "ADMINORG",
status: 2,
url: "enode://7a1e3b5c6ad614086a4e5fb55b6fe0a7cf7a7ac92ac3a60e6033de29df14148e7a6a7b4461eb70639df9aa379bd77487937bea0a8da862142b12d326c7285742@127.0.0.1:21001?discport=0"
}, {
orgId: "ADMINORG",
status: 2,
url: "enode://5085e86db5324ca4a55aeccfbb35befb412def36e6bc74f166102796ac3c8af3cc83a5dec9c32e6fd6d359b779dba9a911da8f3e722cb11eb4e10694c59fd4a1@127.0.0.1:21002?discport=0"
}, {
orgId: "ADMINORG",
status: 2,
url: "enode://28a4afcf56ee5e435c65b9581fc36896cc684695fa1db83c9568de4353dc6664b5cab09694d9427e9cf26a5cd2ac2fb45a63b43bb24e46ee121f21beb3a7865e@127.0.0.1:21003?discport=0"
}],
roleList: [{
access: 3,
active: true,
isAdmin: true,
isVoter: true,
orgId: "ADMINORG",
roleId: "ADMIN"
}],
subOrgList: null
}
提议新组织加入网络
一旦网络部署完成以后,网络管理员账号可以提议一个新的组织加入网络。网络中所有的管理员账号会对这件事进行投票,投票通过后新组织被允许加入网络。
具体操作执行可以查看API文档中的proposing 和 approving 操作
具体步骤示意可以查看官方文档说明
https://docs.goquorum.com/en/latest/Permissioning/Usage/#proposing-a-new-organization-into-the-network
步骤
提议
查看提议的组织状态 投票
投票结果超过半数,同意新组织节点加入 新组织的节点加入网络。如果当前网络使用的是raft共识,需要注意,在新组织节点加入网络时要确保:
1,新的节点在raft层已经被添加为peer raft.addPeer(\<\<enodeId>>)
2,根据上一步获得的raft peer id,使用geth以--raftjoinexisting模式启动新节点
组织管理员管理和准入许可
> quorumPermission.addSubOrg("ORG1", "SUB1", "enode://239c1f044a2b03b6c4713109af036b775c5418fe4ca63b04b1ce00124af00ddab7cc088fc46020cdc783b6207efe624551be4c06a994993d8d70f684688fb7cf@127.0.0.1:21006?discport=0", {from: eth.accounts[0]})
"Action completed successfully"
> quorumPermission.getOrgDetails("ORG1.SUB1")
{
acctList: null,
nodeList: [{
orgId: "ORG1.SUB1",
status: 2,
url: "enode://239c1f044a2b03b6c4713109af036b775c5418fe4ca63b04b1ce00124af00ddab7cc088fc46020cdc783b6207efe624551be4c06a994993d8d70f684688fb7cf@127.0.0.1:21006?discport=0"
}],
roleList: null,
subOrgList: null
}
添加子机构并不是强制性的,如果机构管理员想为新创建的子机构添加一个管理账号,那么机构管理员首先需要
创建一个具有isAdmin权限的角色,并赋予子机构下某个账户这个角色 API 将新建的角色赋予子机构的账号 需要注意的一点,上级机构拥有本机构和自己子机构的所有管理权限,而子机构管理员只拥有自己组织的管理权限。
暂停某个机构
网络管理员(Network Admin) 提议修改某个组织的状态为“暂时关闭”所有网络管理员针对此条提议进行投票
组织层/网络层管理权限的授予
在某些情况下,我们可以一个账号同时具有机构管理员的权限和网络管理员的权限。同样也是需要进过两个步骤
1,提议
2,投票