因为最近在用Python写几个爬虫,一直是在用re的正则去匹配自己想要的内容 虽然也是很灵活,但是有时候还是写起来很麻烦 了解到XPath这种神器,简单学习了一下,果然好用。
基础概念
节点(Node)
在 XPath 中,有七种类型的节点:元素、属性、文本、命名空间、处理指令、注释以及文档(根)节点。 

基本值(或称原子值,Atomic value)
基本值是无父或无子的节点。
项目(Item)
项目是基本值或者节点。
节点关系
父(Parent)
每个元素以及属性都有一个父。
子(Children)
元素节点可有零个、一个或多个子。
同胞(Sibling)
拥有相同的父的节点
先辈(Ancestor)
某节点的父、父的父,等等。
后代(Descendant)
某个节点的子,子的子,等等。
谓语(Predicates)
谓语用来查找某个特定的节点或者包含某个指定的值的节点。 谓语被嵌在方括号中
轴
轴可定义相对于当前节点的节点集。 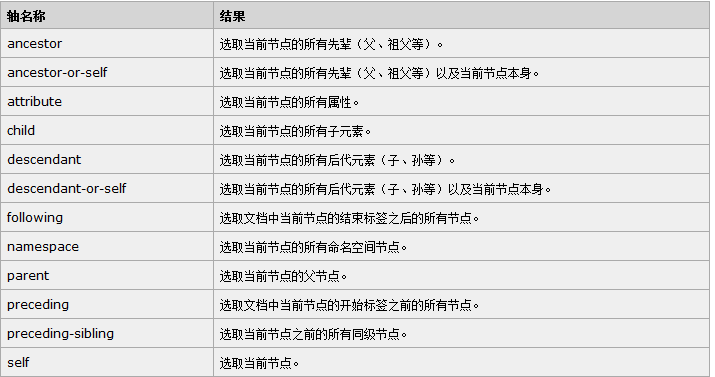
XPath运算符
此处略 比较简单 XPath的路径表示,有点像Linux的文件系统 从"/"开始的是绝对路径 与之相对的当然是相对路径
/step/step/...
step/step/...
step(步)包括 轴名称::节点测试[谓语] 三部分 通过具体代码简单实验一下 使用Python代码爬虫,要先安装XPath,直接pip安装就好
from lxml import etree
import requests
def spider(url):
html = requests.get(url)
selector = etree.HTML(html.text)
content_field = selector.xpath('//div[@class="zm-editable-content"]')
item = {}
for each in content_field:
the_true = each.xpath('img[@src]')
text = each.xpath('br/text()')
info = data.xpath('string(.)')
info_text = info.replace('\n','').replace(' ','')
item['gakki_text'] = info_text
item['gakki_img_src'] = the_true
f.wirtelines(u'gakki:'item['gakki_text'] + '\n' + ['gakki_img_src'])
if __name__ == '__main__':
f = open('gakki.txt','a')
page = 'http://www.zhihu.com/question/26942050'
results = spider(page)
f.close()